Most digital content is stored in databases. Common resources are:
- journal articles
- e-books
- bibliographic references (of journal articles, books, etc.)
- theses
- conference papers and proceedings
- data (statistical data, measured data from experiments)
Fee-based content
There are publishers who index and provide their digital content in databases themselves. Other companies acquire licenses for digital content from various publishers and index the resources in specialized subject and interdisciplinary databases. These services come at a high cost. Libraries subscribe to a license to allow users to search within the database and download content. In the course of the last decade, prices have soared. This has forced libraries to negotiate digital content in specific packages, and in many cases they can only afford to license a part of the database’s content (often with limitations in subject and publication periods).
Example: EBSCO, Elsevier Science Direct, Wiley online.
Free accessible resources
Besides fee-based databases, there are also freely accessible resources. Free resources are databases or repositories that offer their content free of charge. Their providers are normally non-commercial institutions (such as research institutes, governmental organization or universities).
The price explosion for fee-based digital content has given rise to the Open Access movement in response to the ethical debate about free access to scientific information. The initiative forms standards to publish scientific material for free use under the conditions of copyright control. Most of Open Access content is published in institutional repositories housing theses, proceedings or research data.
Example: Orbilu, ArXiv, HAL, psydoc, DART, DOAJ.
With the increasing acceptance for the publication of scientific information using open access, more and more publishers are making selected content available free of charge.
OpenURL resolver
The online access is generated by a link resolver – the SFX link resolver. This is a software bought by the Consortium Luxembourg in order to link the bibliographic information potentially spread throughout the internet (e.g. a-z.lu, findit.lu or GoogleScholar) to the corresponding document on the publisher’s server (e.g. Springer).
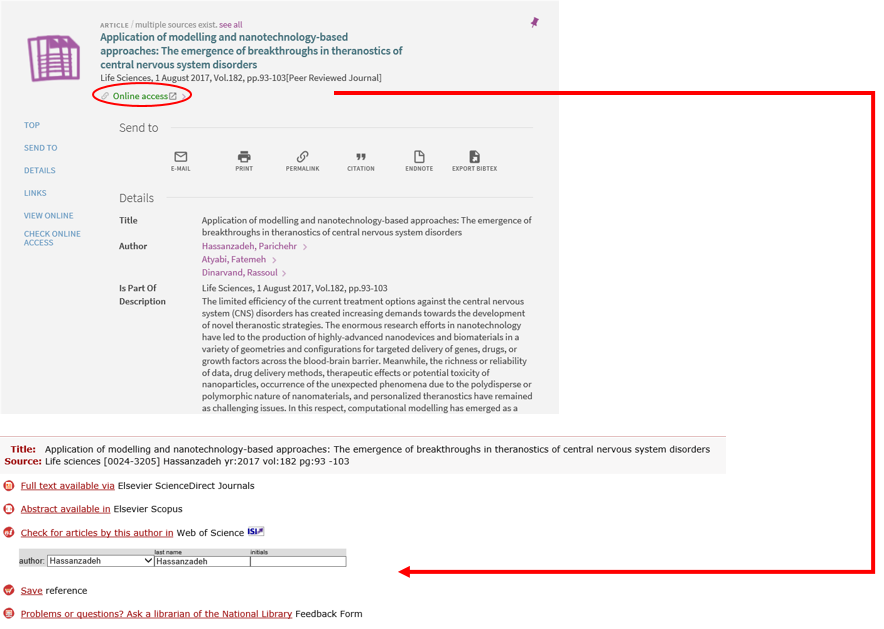
Find more information on the working of a link resolver, click here.